
サイト検索
好評発売中

異境
(オーストラリア現代文学傑作選)
「オーストラリア現代文学傑作選」の第1巻。 オーストラリア文学界の第一人者デイヴィッド・マルーフの代表作。 詩人でもある著者が描く繊細な言葉の世界をご堪能ください。


機械翻訳 しっかり入門
第3章 翻訳ソフトの仕組み
この章では,翻訳ソフトが内部でどのような処理を行っているのか,そしてどんなむずかしさがあるのかを説明します。
まず,翻訳ソフトの親戚とでもいうべきワープロの仕組みがどうなっているか簡単に説明し,それと対照させながら翻訳ソフトの仕組みを説明します。なお,ここでは,ワープロや翻訳ソフトの中心となる仕事(カナ漢字変換と翻訳)について詳しく説明しますが,画面への表示や印刷など,どのソフトでも共通するような機能については,省略します。
3.1 ワープロソフトの仕組み
ワープロソフトはわれわれパソコンユーザーが入力するカナやローマ字を「カナ漢字変換」して,漢字とカナの混ざった日本語の文章にしてくれます。このとき,パソコンの内部ではどのような処理が行われているのでしょうか?
3.1.1 辞書
例を考えてみましょう。次のカナ文字の列がキーボードから入力されてきたとして,それを漢字とカナの混じった日本語の文章に直すにはどうしたらよいでしょうか?
わたしはいま,ほんをかいています。
話を簡単にするため,「わたしはいま」までで変換キーを押した場合を考えて,ここまでを漢字カナ混じり文に変えてみましょう。
ひらがなの列を漢字混じりの文に直すわけですから,まず「対応表」が必要なことは間違いありません。たとえば,次のようなものです。
わたし:私
は:は
いま:今
このような対応表は「辞書」と読ばれています。もし辞書に上の3つの単語だけが入っているとしたら,「わたしはいま」はどう変換されるでしょうか。頭の方から照らし合わせていってみれば,「わたし」が「私」,「は」が「は」,「いま」が「今」にマッチして,「私は今」と変換できます。
ところが,よく考えてみるとこのほかにもたくさんの単語が辞書にある(登録されている)はずです。たとえば,先頭の「わ」だけをとっても,「和」,「輪」,「話」なども「わ」と読むことができます。そして,このような漢字も使われる可能性がありますから,辞書には必ず入れておく必要があります。ではたとえば,次のようなデータが辞書に入っていたとして,「わたしはいま」を変換してみましょう。
わたし:私
わ:和
たし:足し
し:氏
しはい:支配
は:歯
は:は
い:胃
ま:間
いま:今
いま:居間
ジグソーパズルに少し似た感じの,組み合わせの問題になりますが,次のように変換されても文句は言えないことになります。
和足しは今 (和+足し+は+今)
私歯今 (私+歯+今)
和足し歯今 (和+足し+歯+今)
綿氏は居間 (綿+氏+は+居間)
綿氏は胃間 (綿+氏+は+胃+間)
.
.
.
どうやって,このようには変換せずに「私は今」と変換しているのでしょうか? 対応表(辞書)だけでは足りないことは明らかです。このほかにどんな情報を使っているのでしょうか?
3.1.2 文法的情報
日本語(およびそのほかの言語)には「このような順序に並ばなければならない」という規則,つまり「文法」があります。変換した結果が,文法的におかしければその変換は排除することができます。
この文法的な情報を使うためには,対応表(辞書)に文法的な情報を入れておくことと,そのことばの文法をパソコンで扱えるような「文法規則」に表現することが必要になります。
たとえば,先ほどの辞書を次のように変更して,いわゆる「品詞」の情報をつけることにします。
わたし(名詞):私
わ(名詞):和
たし(動詞の連用形):足し
し(名詞):氏
しはい(名詞):支配
は(名詞):歯
は(助詞):は
い(名詞):胃
ま(名詞):間
いま(名詞):今
いま(副詞):今
いま(名詞):居間
そして,次のような順番に並んでいないと,変換してはいけないことにしてみましょう。
名詞+助詞+副詞
たとえば,「和足しは今」はどうでしょうか? 「和」は名詞で,「足し」は動詞の連用形ですから,「和足しは今」は「名詞+助詞+副詞」にはなりません。ですから,上の規則に当てはまらないのです。「私歯今」はどうでしょうか? 「私」は名詞「歯」も名詞ですから,ダメです。「綿氏は居間」も名詞+名詞+助詞+名詞になりますからダメです。これに対して,「私」は名詞,「は」は助詞,「今」は副詞ですから,「私は今」は「名詞+助詞+副詞」の形になっています。ですから「私は今」は上の条件を満たしているわけです。
この例は非常に単純化したものですが,より複雑に精密にした形で文法的な情報を使うことによって,いろいろな可能性の中からおかしな可能性を排除しているのです(図3-1)。

図3-1 文法規則による解の選択
3.1.3 優先度
では,文法的な情報を使えばすべて解決されるのでしょうか? 上の例で「綿氏は居間」という変換がありましたが,これを「綿」という名字をもった人(「綿氏」)は「居間」にいるということを表現していると解釈するのは文法的に誤りでしょうか(上で作った文法規則に照らし合わせればもちろん「誤り」ということになりますが,そうではなくて一般的な日本語の文法を使って解釈してという意味です)。そうとは言い切れません。「綿氏は居間」よりも「私は今」の方が普通だ,可能性が高いということしか言えないのです。
そこで,もうひとつ別の情報が使われているらしいということになります。「この方が確からしい」とか「確率が高そうだ」とかいう情報です。「かんれい」という読みを聞いてどんな漢字を思い浮かべますか。気象庁にでもおつとめの方を除けば,「慣例」と思い浮かべるのではないでしょうか。ワープロ(ソフト)をお使いの方は,「かんれい」を変換してみてください。「慣例」と表示してくれるものが多いと思います。「寒冷」はあるかもしれませんが「管領」などと表示されても意味も分かりません。このような「これの方がよく使われそうだ」という情報(「優先度」,「好み」,「確率」,「ウェイト」,「抵抗値」などと呼ばれます)も使われていることがわかります。
3.2.4 学習
この優先度の問題は,「学習」ということに深く関わってきます。気象庁に勤めている人が「かんれい」を変換したら「慣例」と最初に出てしまったため,もう一度キーを押して次の候補の「寒冷」を表示して,これを選択しました。しばらくして,もう一度「かんれい」と入れたらどちらが出てきてくれた方がうれしいでしょうか? もちろん「寒冷」の方です。優先度の問題は,その人の好みや用途に深く関わってきます。ですから,使う人や用途によって,優先すべきものを「学習」してくれると,ワープロソフトも使いやすくなるわけです。
3.2.4 意味情報
ここまでで,ワープロソフトは「辞書」と「文法」を中心にして,それに「優先度」の情報も利用して変換を行っていること,そして「学習」によって使いやすさを増していることを説明しました。
さて,大事な要素が抜けていると思われませんか? 文章を書くのは何かを伝えたいからです。(普通は)その文章を書くことに「意味」があるから書くわけです。ワープロソフトでは,意味的な情報は使っていないのでしょうか? そもそも,「和足しは今」も「私歯今」も,意味をなさないので排除してしまえばよいのではないでしょうか?
ところがコンピュータを使って「意味」を表現するのは非常に難しく,この情報を本格的に使ったワープロソフトはないのです。次のひらがなの列を考えてみてください。
りんごはたかいやまにくだってぱそこんでせんたくをした。
これを私の使っているワープロソフトに入力すると次のように変換してくれます。
リンゴは高い山に下ってパソコンで洗濯をした。
この文は,文法的には(意味を考えに入れないで)誤りはありません。ですが,意味的にはよくわからない文章です。そもそもリンゴが洗濯などするのでしょうか? 「高い山にのぼる」のならばわかりますが「高い山に下る」とはいったいなんでしょうか? しかし,ワープロソフトはそんなことは考えずに変換をしてくれます。これを拒絶するには膨大な知識がいるのです。この文だけを考えても,人間がおかしいと思うところでは次のような知識を使っています。
- リンゴは洗濯はしない。
- 山には登るものであって,山に下ることは普通はない。
- パソコンで洗濯はしない。
このような知識をすべての物体,すべての概念について整合性をもった形で用意しないと意味を完全に理解することはできないのです。これは深入りすれば深入りするほどむずかしい問題です。
最近のワープロソフトでは,わずかながら意味情報を利用しているものがあります。典型的な例は「動詞とその目的語」の関係を使ったものです。たとえば私が使っているワープロソフトで,「にほんごをかく」を変換すると「日本語を書く」となりますが,そのあとすぐに「がりょうてんせいをかく」を変換すると「画竜点睛を欠く」と変換してくれます。この場合は「画竜点睛」は「欠く」という動詞を伴って使われるという情報が入っているわけです。さらに,「いいんをせんこうする」を変換すると「委員を選考する」となりますが,つづいて「えいごをせんこうする」を変換すると「英語を専攻する」と変換してくれます。こういった意味情報を利用していくことにより,より使いやすいソフトを作ろうとしているわけです。
いずれにしろ,この程度の意味情報が利用されているにすぎません(これでも大きな進歩だということはできるとは思いますが)。ワープロソフトで使われているのは辞書と構文と優先度が中心だというわけです。
3.2 翻訳ソフトの仕組み
では,翻訳ソフトの場合はどうなっているのでしょうか? ワープロソフトや人間が翻訳する場合と対比しながら見ていきましょう。ここでは,英語の文章を日本語に翻訳する場合を考えます。
ワープロソフトでは,辞書と文法を中心に,優先度の情報を使って変換を行っていました。さらに,学習機能によって使いやすくしています。翻訳ソフトの場合はどうでしょうか?
3.2.1 辞書引き
翻訳をするのに辞書がなければ話になりません。人間は頭の中にかなりの単語を記憶していますから,翻訳をするのにあまり辞書を引く必要のない場合もありますが,翻訳ソフトの場合は,翻訳ソフトの使う「辞書」が人間の頭の中に記憶されている単語にあたるわけで,この辞書がないことには英語から日本語への翻訳(変換)はまったくできないわけです(そのかわり,人間と違って,コンピュータが記憶したことを忘れるということはありません。どんなに長い単語でも,一度入れてしまえばそれ以後は必ず訳が出てくることになります)。
翻訳ソフトでも,まず辞書をみて単語の性質(品詞)や意味(訳)を取り出します。この操作のことを「辞書引き」と呼びます。次の例文を見てみましょう。
I bought a book yesterday.
この文を辞書引きすると,たとえば次のような情報が得られます。
I:代名詞:「私」
bought:他動詞過去形:「を買った」
bought:自動詞過去形:「買い物をした」
a:冠詞:(訳なし)または「ひとつの」または「1冊の」または「1本の」
book:他動詞原型:「を予約する」
book:名詞:「本」
yesterday:副詞:「昨日」
.:ピリオド:「。」
上の「辞書データ」は,左から,英語の単語,品詞,訳の順に並んでいます。実際の辞書データはコンピュータであつかいやすいように記述されています。ここに示したのは,人間にとってわかりやすく書いたもので,このままが使われるわけではなりません。
情報がこれだけしかないとなると,I bought a book yesterday.を,たとえばbookを他動詞だと解釈して
代名詞+他動詞+冠詞+他動詞+副詞
(「私 を買った 一本の を予約する 昨日。」)
とか,boughtを自動詞だととって
代名詞+自動詞+冠詞+名詞+副詞
(「私 買い物をする 本 昨日。」)
といったように並べても「別に悪くないかな」ということになります。ワープロの例で,「わたしはいま」を「和足しは今」と変換するようなものです。
3.2.2 構文解析
ワープロで使われていた文法的な情報は使われるのでしょうか? 人間が翻訳するときも当然,文法的(構文的)な情報を使っています。文法的な情報を使って,主語はどれで,動詞はどれで,目的語がどれでといったことを(意識してか無意識にかはわかりませんが)認識して,意味をとらえて翻訳しています。翻訳ソフトの場合も,構文情報を使っています。
構文情報は,たとえば,次のような規則(制限)を導入すれば,上のようなおかしな解釈を排除できることになります。
文 ← 代名詞+他動詞+冠詞+名詞+副詞+ピリオド
この規則は,「右側のような品詞の列からなっているものは(英語の)文ということができる」ということを表しています(ワープロの場合は必ずしも文全体を一度に変換する必要はありませんが,翻訳ソフトの場合は原則として1文単位で翻訳していきます)。この規則にあてはまるようにするには,boughtを他動詞(「を買った」),bookを名詞(「本」)と解釈せざるを得ません。このような規則のことを文法規則といい,この文法規則を満たしているか解析することを「構文解析」と呼んでいます。
構文解析の結果は「構文解析木」を使って表すと便利です。上の規則を使って I bought a book yesterday. の文を解析した結果を構文解析木として表すと,図3-2のようになります。
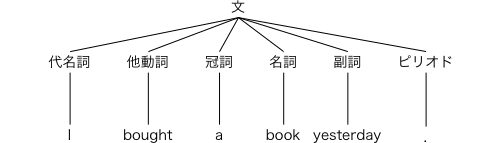
図3-2 構文解析木
この構文解析によって,たくさんある可能性の中から妥当なものを絞り込んでいきます。たとえば,boughtには,自動詞も他動心もありますが,自動詞だととっても(この場合はひとつしかない)規則が満たされなくなってしまうため,自動詞だという可能性はなくなるわけです(図3-3)。
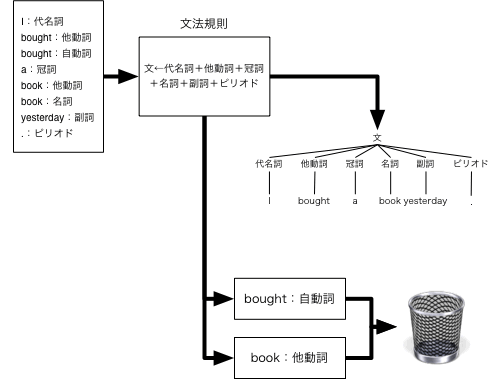
図3-3 構文解析による可能性の絞り込み
3.2.3 優先度
ワープロで使われていた優先度はどうでしょうか? この辺になると翻訳システムによって,考え方がだいぶ変わってきますが,多くのシステムでは,この優先度がかなり重要な役割を占めています。後ほど具体的な例をお見せしましょう。
3.2.4 学習
さて,翻訳ソフトは学習するのでしょうか? 昔の翻訳システムでは,学習はほとんど考えられませんでした。というのは,対話的なシステムではなかったからです。一度に全部を翻訳してしまうだけで,利用者が訳語を対話的に選択したりはできませんでした。しかし,最近の翻訳ソフトでは,学習機能を使ってより使いやすくする工夫をしています。ただし,ワープロソフトと翻訳ソフトでは,学習する内容がだいぶ違っています。
3.2.5 意味情報の利用
意味情報はどうでしょうか? 意味を考えないで翻訳なんてできないと思いませんか? 少なくとも,人間の翻訳者はほとんどの場合,意味を取りながら翻訳しています。ですから,当然どんなにむずかしいとはいっても,翻訳ソフトでも何らかの形で意味を把握せずには翻訳はできないはずです。
ところが,ほとんどの翻訳ソフトでは,じつは最新のワープロと同じ程度にしか意味情報は使っていないのです。信じられますか? 翻訳をしているのに,意味が分からずにやっているのです。そんなことで「翻訳」はできるのでしょうか?
できるのです。じつは翻訳者が翻訳する場合でも,意味はよく分からないが,構文(文法)を頼りに訳さなければならない場面があるのです。翻訳者が完全に知っている分野の翻訳だけをして生きていけたらよいのですが,なかなかそうはいきません。どんなにがんばってみても,わからないときがあるのです。そのときはどうするかというと,辞書を一生懸命引いて(百科事典や各種の専門書などのお世話になることもあります),文法的な知識を総動員して,構文的に誤りのないわかる範囲でベストの翻訳をするのです。そして,そのような訳文をその分野の知識がある人が読むと通じてしまうのです。苦し紛れの翻訳をして,何とか役に立つ結果を出しているのです。
翻訳ソフトの処理は,この「苦し紛れの翻訳」に非常に近いものです。意味をきちんと理解はしていないが,辞書にある情報と文法規則とを徹底的に調べあげて,何とか日本語に置き換えているわけです。意味が分かっていないからといって,全然使いものにならないとは言い切れないのです。
以上をまとめると,ワープロソフトで使われている情報は,ほとんど翻訳ソフトでも使われているということになります。細部にいろいろな違いはありますが,かなり似ていることがわかります。辞書(対応表)も文法も優先度も使われており,意味情報は少ししか使われていません。
3.2.6 ワープロソフトとの違い
さて,ワープロソフトと翻訳ソフトの根本的な違いは,翻訳ソフトでは2つの言語を扱うということでした。辞書と文法と使って解釈できるのは,入力である英語の文章であって,このままでは日本語の文章にはなりません。何らかの形で日本語に変換する必要があります。
3.2.6.1 変形規則
翻訳者は,まず英語の原文を読んで(普通は)内容を理解し,それと同じ意味と印象をもつ日本語に変換します。たとえば次の文を考えてみましょう。
I bought a book yesterday.
この文は単純な文ですから,読めばすぐに「昨日を本を買った。」とか「私は,昨日1冊本を買いました。」とか「きのう,本買っちゃったよ。」といった文に直すことができます。次の文はどうでしょうか。
I bought a phidrosolanspy yesterday.
おそらくphidrosolanspyという単語の意味は知らないでしょうから,まず辞書を引くでしょう。そこに意味が載っていればよいのですが,あいにく小さな辞書しか手元になくてその辞書には載っていません。でも周囲との関係から,これは名詞に違いないはずだから,「昨日,phidrosolanspyを買いました」となることは間違いないだろうということはわかります。あとで,phidrosolanspyに対応する日本語が分かったところで,そこに入れればよいわけです(なお,phidrosolanspyという単語は私が説明のために適当に作った単語で,英語の単語ではありません)。
このような手順をパソコンでも使えるようにすればよいわけです。つまり,何らかの形で,英語の構文を日本語の構文に対応させてやる必要があるわけです。英語の構文から日本語の構文への対応付けのことを「変形」,「変形操作」,「構造変換」などと呼びます。
では,この例をもう少し進めて,具体的な変形の手順を記述してみることにしましょう。一番単純な形式で表せば,たとえば次のように書くこことができます。
I + bought + a + 名詞 + yesterday + .
→ 昨日<名詞>を買った。
ここで,<名詞>は,あとでこの名詞を対応する日本語に置き換える必要があることを示します。名詞がbookに変われば,「昨日<book>を買った。」となり,この<book>が対応する日本語の「本」に変われば「昨日本を買った。」となるわけです。このように構造の変形を記述した規則のことを「変形規則」と呼びます。
I bought a 名詞 yesterday. とうまく並んでくれる英文はとても少ないですから,これをより一般化して次のような変形規則で表せば,多くの文に対して使えるようになります。
変形規則(1)
I + 他動詞 + 冠詞 + 名詞 + 副詞 + .
→ <副詞> + <名詞> + <他動詞> + 。
この規則を使えば,次のような文の「変形」操作がすべてできてしまうことになります(話を簡単にするため,last week,last year, the day before yesterday などをすべて副詞として1語で扱うことにしましょう)。
I sold the computer last week.
→ <last week><sold><computer>。
I worte a book last year.
→ <last year><worte><book>。
I sent a letter the day before yesterday.
→ <the day before yesterday><sent><letter>。
この変形規則(1)は構文木を別の構文木に変形する規則だと見ることもできます。図3-4の上の構造が,下の構造に「変形」された訳です。

図3-4 木構造の変形
さあ,ここまでできてしまえば,後少しです。残るは,対応する日本語をあてはめればよいのです。
3.2.6.2 生成
さて,上の変形規則(1)の適用によって得られた結果の,<last week>,<sold>などにこれに対応する日本語を当てはめてみましょう。
I sold the computer last week.
→ <last week><sold><computer>。
→ 先週本を売った。
I worte a book last year.
→ <last year><worte><book>。
→ 去年本を書いた。
I sent a letter the day before yesterday.
→ <the day before yesterday><sent><letter>。
→ 一昨日手紙を送った。
めでたしめでたし,見事に翻訳されました。この,訳語を当てはめて最終的な日本語を出す操作を「生成」操作と呼びます。生成の仕方を規則に表した場合は,その規則のことを「生成規則」と呼びます。上のような単純な例では単に「対応する訳語で置き換える」というだけですが,より複雑な規則が必要になるのが普通です。
「構造変形」と「生成」の操作は,ワープロソフトにはない操作です。つまり,翻訳ソフトには「変形規則」と「生成規則」が加わっているのです。
いかがでしょうか。だいぶおおざっぱな説明ですが,翻訳ソフトがどんな情報(データ)を使って,どんな処理をしているのか,だいたいおわかりいただけたでしょうか。
3.3 全体の流れ
さて,上の説明では,ワープロソフトと翻訳ソフトとの比較に重点をおいて,翻訳ソフトがどのような処理をして日本語に変換しているかを説明しました。それぞれパート(モジュール)を独立に説明し,各パートがどのように関連づけられているか(たとえば,辞書引きと構文解析はどう関係しているか)には詳しく触れませんでした。実際の翻訳処理では,上で説明したような処理が,何の関係もなく行われるわけではなく,それぞれのパートには密接な関係があります。この節では,翻訳処理の全体の流れを詳しく説明します。 なお,必ずしもすべての翻訳ソフト(翻訳システム)の構造が以下のようになっているわけではないことをお断りしておきます。
3.3.1 翻訳ソフトの内部構造
翻訳ソフトの内部で使う情報(データ)としては次のものがあります。
- 辞書
- 文法(構文)規則
- 変形規則
- 生成規則
このほかにも,優先度の情報と意味情報が使われていますが,これらは辞書,文法,変形規則,生成規則に埋め込まれる形で入っており,独立したデータ(ファイル)とはなっていません。
これだけのデータを使って翻訳処理を行うわけですが,その処理の手順は以下のような過程(部分)に分けることができます。
- 辞書引き
- 構文解析
- 構造変形
- 生成
翻訳ソフトで使われるデータと各処理過程の関係を図に表すと図3-5のようになります。

図3-5 翻訳ソフトの処理過程
これを具体的な例を見ながら説明していきましょう。上の例で使った,次の例文で見てみることにしましょう。
I bought a book yesterday.
3.3.2 辞書引き
まず行われるのが,辞書引きです。文を頭から見ていって,各単語を辞書のデータと照合していくわけです。この辞書引きによって,それぞれの単語に下のような情報が付加されます。
I:代名詞(主格):「私」
bought:他動詞(過去形):「買う」。目的語の後に「を」を送る
bought:自動詞(過去形):「買い物をする」
a:冠詞(不定冠詞):「ひとつの」。本を修飾する場合は「1冊の」。鉛筆などの場合は「1本の」
a:前置詞:「につき」
book:他動詞(原型):「予約する」。目的語の後に「を」を送る
book:名詞(加算):「本」
yesterday:副詞(時を表す):「昨日」
yesterday:名詞:「昨日」
.:ピリオド:「。」
この形式は,前節の辞書に関する説明とほぼ同じですが,より詳しいものになっています。ここで注意していただきたいことは,ひとつの単語が複数の品詞をもち,そしてそれぞれの品詞で,また複数の意味があるということです。翻訳ソフトの内部処理の大きなポイントは,この中のどの品詞を採用し,その品詞のどの意味を採用するかということなのです。
3.3.3 構文解析
辞書引きされたデータは構文解析に渡されます。構文解析にはたとえば下のような一群の文法規則(文法2)が使われます。
文法2
(1) 名詞句 ← 代名詞
(2) 名詞句 ← 冠詞+名詞
(3) 動詞句 ← 自動詞
(4) 動詞句 ← 他動詞+名詞句
(5) 動詞句 ← 自動詞+副詞
(6) 動詞句 ← 他動詞+名詞句+副詞
(7) 節 ← 名詞句+動詞句
(8) 名詞句 ← 節
(9) 文 ← 節+ピリオド
前の節の説明では次のひとつの規則しか利用しませんでした。
文 ← 代名詞+他動詞+冠詞+名詞+副詞+ピリオド
この文法規則の右の側(右辺)には「名詞」とか「動詞」など具体的な品詞しか出てきませんでしたが,翻訳ソフトの構文解析では,「名詞句」「動詞句」「節」といった最終的な文にいたる,中間的なまとまりを表すものを導入しています。
この文法規則をどう読むかを説明しましょう。文法規則(2)は「冠詞と名詞がこの順番で現れると名詞句ができます」ということです。(1)は「代名詞はそれだけで名詞句にまります」ということを表します。この2つは品詞から中間的なまとまりを作る例でしたが,文法規則(7)は「何らかの方法で名詞句と動詞句がこの順番で並んだらそれは節になる」ということを表しています。
このような文法規則を使って,上の文(I bought a book yesterday.)を「解析」して見ましょう。
- まず,I(代名詞)は名詞句になります(文法2の(1)).
名詞句(I) ← 代名詞(I)
- boughtを自動詞としてとると,boughtだけで動詞句を形作ることになります(文法2の(3)).
動詞句(bought) ← 自動詞(bought)
- a(冠詞)とbook(名詞)で名詞句になります(文法2の(2)).
名詞句(a book) ← 冠詞(a)+名詞(book)
- boughtを他動詞としてとったものとa bookでできた名詞句で動詞句ができます(文法2の(4)).
動詞句(bought a book) ← 他動詞(bought)+名詞句(a book)
- boughtを他動詞としてとったものとa bookでできた名詞句とyesterday(副詞)でも動詞句ができます(文法2の(6)).
動詞句(bought a book yesterday) ← 他動詞(bought)+名詞句(a book)+副詞(yesterday)
- 1.でできた名詞句(I)と4.でできた動詞句(bought a book)で節(I bought a book)ができます(文法2の(7)).
節(I bought a book)← 名詞句(I)+動詞句(bought a book)
- 1.でできた名詞句(I)と5.でできた動詞句(bought a book yesterday)で節(I bought a book yesterday)ができます(文法2の(7)).
節(I bought a book yesterday) ← 名詞句(I)+動詞句(bought a book yesterday)
- 6.でできた節(I bought a book)は名詞句(I bought a book)になります(文法2の(8)).
名詞句(I bought a book)← 節(I bought a book)
- 7.でできた節(I bought a book yesterday)は名詞句(I bought a book yesterday)になります(文法2の(8)).
名詞句(I bought a book yesterday)← 節(I bought a book yesterday)
- 7.でできた節(I bought a book yesterday)とピリオド(.)で文(I bought a book yesterday.)ができます(文法2の(9)).
文(I bought a book yesterday.) ← 節(I bought a book yesterday)+ピリオド(.)
このように文法規則を適用して,少しずつ大きなまとまりを作っていくという操作を繰り返していって,上の9.で最終的に「文」になります。この最終的に文になったものの文法規則の適用の様子を書くと,図3-6のような構文木ができあがります。

図3-6 I bought a book.を解析して得られる構文木
この図のかっこの中に書かれている数字は,その要素を作るときに適用した文法規則の番号を表します。たとえば,一番上の「文」を作る際には文法規則の(9)が適用されました。構文解析木を見ると,規則の適用の様子,つまり文の構造がわかるようになっています。前節の説明では,1次元的な品詞の列として文法を記述しましたが,このような形で文法を記述すると,2次元的な構造が明らかになるといってもよいでしょう。
途中で作られた構造には,最終的には使われずに捨てられてしまうものがあります。2.で作られるboughtだけからなる動詞句や6.で作られるI bought a bookからなる節)。この操作によって,品詞や構造の絞り込みを行っているわけです(図3-7)。
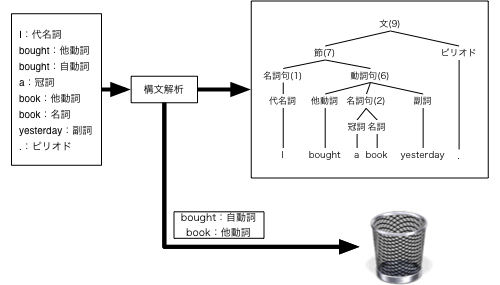
図3-7 構文解析による品詞や構造の絞り込み
少し話が本筋からそれますが,(8)の規則に注目してください。この規則では「節は名詞句を構成することができる」といっています。(2)では,名詞句と動詞句が集まって節になるといっていますから,名詞句は節に含まれ,その節はまた名詞に含まれるという,次のような関係が成り立つことになります。
名詞句 < 節 < 名詞句
この規則はじつは次のような文を構文解析するのに使われるのです。
I know that he bought a book yesterday.
この文では,know の目的語が節になっています。名詞句の中に別の名詞句が入っている,「再起的な」「入れ子」構造なのです。このように,自分(名詞句)の中に自分(名詞句)を含むような構造をもつということは,自然言語の大きな特徴であり,これによって,いくらでも長い文を作ることができるようになっています。
これで,構文解析が終わりました。では次の段階,構造変形の過程に入りましょう。
3.3.4 変形
変形の過程では,構文解析で作った構造を,日本語の生成の際に便利な構造に変形する操作を行います。つまり,この過程を表す規則は,構文木から構文木への変換を表すものになるわけです。
この規則の例をあげましょう。下の図3-8を見てください。この規則では,「名詞句は冠詞と名詞から成る」という構造を「名詞は冠詞に修飾される」という関係に置き換えているものです。
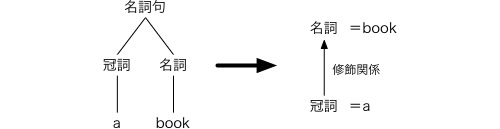
図3-8 変形操作
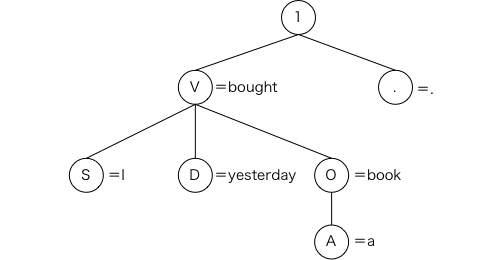
図3-9 変形の結果
一番上にくるのは「1」のノードです(ノードとは木構造の節の部分のことをいいます)。このノードは全体を束ねるためにあるものです。その下に動詞boughtに対応する Vノードと,最後のピリオドを表す「.」ノードがきています。さらに,その下に,主語(Subject)になるIに対応するSノードと時を表す副詞(aDverb)のDノード(yesterday),そして目的語(Object)を表すOノード(book)がついています。このVノードとその下にあるノードを見れば,この文の骨格が表現されていると言えます。一般的によくいわれるところの5W1H(の一部)が表現されているといってもよいかもしれません。この文の登場人物はIとbookであり,したことはboughtという行為,そしてそれをyesterdayに行なったというわけです。
この構造は,「修飾されるものと修飾するもの」の関係を表すだけでなく,日本語の訳順を表すものにもなっているのです。図3-10のように左から右,下から上にこの木をたどってみてください。
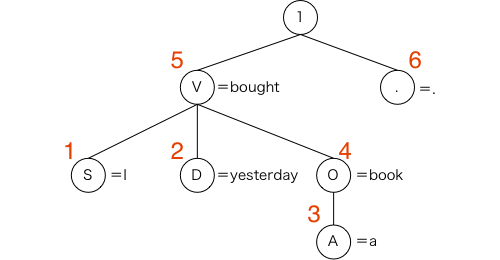
図3-10 生成順序
すると次のような順番になるはずです。
I → yesterday → a → book → bought → .
ここから後は,最後の生成過程の仕事です。
3.3.5 生成
変形操作による木構造の変形によって,ほぼ日本語の訳順を表すようになっています。たとえば,上の英語を順番に日本語に置き換えていくと,「私昨日1つの本買った」という,日本語を学習し始めたばかりの外国人のような日本語になります。
一番最初の辞書引きのところをもう一度見てください。たとえば,a の冠詞の場合の訳語のところを見ると,「本を修飾する場合は『1冊の』」という記述があります。生成の段階ではこういった情報を使いながら訳を生成していくのです。この場合はaがbookを修飾していますから,a bookは「1冊の本」となるわけです。
boughtの他動詞のところには「目的語の後に『を』を送る」という記述があります。ですから,本という目的語の後に「を」が送られ,「本を」という訳が出されます。
Iのところには「私」という訳詞かありませんが,Iは動詞の主語(主格)になっています。『主語の後には普通は「は」を送る』という規則を作っておけば,Iとboughtの関係から,Iは「私は」と訳されることになります。
辞書に書かれている情報とノード間の関係を使って,訳語や助詞などが選択され,最終的に次のような訳文が出されることになります。
私は昨日1冊の本を買いました。
3.4 コンピュータによる翻訳のむずかしさ
上で説明したような処理が行われて,とにもかくにも英語の文が日本語の文に翻訳されて表示されるわけですが,じつはこの処理に大きな問題があるのです。ワープロソフトのところでも,すぐ上の節でも書きましたが,まだコンピュータでは「意味」を「理解」することはできません。「意味を理解する」というのはかなり哲学的な問題で,人間が意味を理解しているというのはどういう状態をいうのかさえよくわかっていないのですから,これをコンピュータで完全に扱えるようにするというのもかなり無茶な話です。
そこで,構文的な情報を中心に,一部意味的な情報を使って処理をしているわけです。ところが,このような情報を使っただけでは,解決できない問題がたくさんあるのです。
3.4.1 曖昧な文
次の例は古典的に有名な文ですから,ここで皆さんに紹介しておきましょう。
Time flies like an arrow.
この文の意味はご存じの方が多いと思います。直訳すると「時は矢のように飛ぶ」,日本語のことわざで対応するものをもってくると「光陰矢のごとし」ということになります。ほかの意味など考えられないと思います。
ところがある日,遺伝子工学を専攻する科学者によってtime fly(トキバエ)というハエが「発明」され,そのハエは矢がとても好きだった。矢を見つけると,いつもそこに飛んでいった,としましょう。この文脈で上の文を読んでみてください。
Time flies like an arrow.
トキバエは矢が好きなんです。
今度は,ある別の科学者がめちゃくちゃに速く飛ぶハエを「発明」したとしましょう。そのハエは,矢のように速く飛ぶんだそうです。いったいどのくらい速く飛ぶんだろうというわけで,このハエが100m飛ぶのにかかる時間を計ることにしました。その科学者が,部下に命令します。
Time flies like an arrow!
このtimeは動詞で,「時間を計測せよ」とか「タイムを計れ」という意味です(timeに動詞があるなんてご存じでしたか?)。日本語にすると,
矢のようなハエのタイムを計れ!
とでもいうことになりましょうか。といった具合で,この単純に思える文にも数多くの解釈があるのです。人間の書く文は非常に曖昧(あいまい)なのです。
3.4.2 文法の不備による曖昧さ
上の例は,人間の書く文がそれ自体にもっている曖昧さの例ですが,翻訳ソフトで使われる文法や辞書の記述によって,「人工的な曖昧さ」とでもいうべきものも発生します。次の文を例にして考えてみます。
I bought a book.
この文には,どう考えても「私は本を1冊買った。」に相当する解釈しかないように思われるでしょうが,これを意図的に曖昧にするのは非常に簡単なのです。
aはどうやっても定冠詞だろうと思われるかもしれませんが,次の文の a も定冠詞といえるでしょうか?
I see him once a week.
(私は1週間に1度彼に会います。)
辞書では確かに冠詞の分類をされていますが,冠詞というよりは「〜につき」という意味を表す前置詞のような使われ方をしています。そこで,a を前置詞としても登録することにしておくことにすれば,このような文も比較的簡単に解析できるようになります(詳細は省略します)。ところが,そうすると今度は I bought a book. が「私は本につき買い物をした」というふうに解釈できるようになってしまうのです。
boughtには「買い物をする」という意味の自動詞もあります。a が前置詞にもなるとなると,a bookで前置詞句(in the parkのような前置詞と名詞句でひとつのまとまりになるもの)と解釈できることになります。つまり下の文と同じような構文として解釈できるわけです。
I live with my parents.
(私は両親と一緒に暮らしています。)
図3-11にこの2文の構造の対応関係を示しました。

図3-11 I live with my parentsとI bought a bookの構文の比較
この例は単純な例ですから,実際には「私は本につき買い物をした。」という解釈は出さないように,文法規則を書くことはできます。ですが,全体の処理との整合性から,文法規則をいたずらに細かくすることが困難な場合は,こういった曖昧さを招くことに目をつぶらざるを得ない場合もあるのです。
このような「人工的な曖昧さ」と英語や日本語などの自然言語が「本来もつ曖昧さ」とが合わさると,すさまじい数の組み合わせが出てくるのです。たとえば,次の文を考えてみてください
I bought a book and time flies like an arrow.
この文は2つの文をandで結んだものですが,かりにI bought a bookで2つの解釈があって,time flies like an arrowで3つの解釈があったとすると(実際はもっとあります),andで結ばれたこの文は2×3=6個の解釈をもつことになります。ある翻訳ソフトを使って,40語ぐらいの長さの文の曖昧さを計算したところ,なんと100万通りもの構文的な解釈が出てきたことがありました。翻訳ソフトの内部では,この曖昧さとの壮絶な戦いが行われているわけです。
3.5 曖昧さに対する対策
では,このような曖昧さにどのように対処しているのでしょうか? 多くのシステムでは,前に説明した「優先度」をフルに使っています。ふたたび次の例で見てみましょう。
Time flies like an arrow.
「timeの品詞は何?」と聞かれたら,「名詞」と答えてしまいませんか? 「動詞と名詞」でも,じつは不正解なのです。辞書を開いてtimeの項を見てください。「形容詞」としても載っていませんか? 人間は,品詞を全部いつも意識はしていません。一番よく使われる品詞とか,ほとんど聞かない品詞とかいう区別をしていると考えられるわけです。
このような使われ方の頻度を有効に利用すれば,かなりの場合に人間が「正しい」と思う解釈が選択できるのです。この例でみると,timeは名詞で使われることが一番多いから,timeが動詞になっている「ハエのタイムを計れ」という解釈は,あまり可能性がなさそうだということになります。同じように,flyと聞いたら普通は動詞を思い浮かべると思いますから,動詞の方をハエという名詞の解釈より優先することにします。これによって,「トキバエは...」という解釈の可能性はあまりなさそうだということになります。このようにして,結局「時は矢のように飛ぶ」という解釈が採用されるようになるわけです。
多くのシステムでは,すべての単語のすべての品詞について,このような優先順位(重み)をつけています。さらに,文法規則についても,「この規則は使いやすい規則」だとか「これは,かなり特別な場合にしか使われないはずだ」とかいった優先度を使っています。
もちろん,優先度だけではうまくいかない場合もあります。翻訳ソフトの方では,こちらの方が確率が高そうだと思ったが,人間はそうは思わなかったという場合もあるのです。そのような場合に備えて,利用者が区切り位置を示す「フレーズ指定」などの機能が用意されています。